使用AI提取历年漏洞Fofa查询语句
前言
近期使用Rust开发了一个基于流水线的AI助手,名字叫Qpipe,本文将演示我如何使用它来提取历年所有漏洞相关资产的查询语句。
开源链接:https://github.com/Rvn0xsy/Qpipe
最近智谱开放了国内首个大模型免费API接口,我就想着能否用它做一点事情,第一个想到的是把这两年披露的漏洞做一个梳理,就先从网络空间搜索引擎的语法开始。
在特殊时期、特殊渠道被披露的漏洞一般都会有[Markdown]格式的文档来描述漏洞涉及的资产(查询语句),并且附带了PoC的HTTP数据包,因此唯一需要做的就是把文档喂给AI,让AI提取结构化的查询语句。
AI Prompt
$ Qpipe -h
Usage: Qpipe [OPTIONS]
Options:
-c, --config <FILE> Sets a custom config file
-d, --debug
-h, --help Print help
-V, --version Print version
先将Qpipe下载到本地,然后编写特定的配置文件:
model: "glm-4-flash"
api_key: "API_KEY"
url: "https://open.bigmodel.cn/api/paas/v4/chat/completions"
server: "127.0.0.1:3000"
process_group:
- name: "document_search"
cron: "now"
prompt: >
你现在是一个数据提取专家,请在我提供的文档上下文中找出 `Fofa/fofa` 下方的语句, 并总结一个漏洞标题。
按照如下格式输出:
<Title>漏洞标题</Title>,<Fofa>语句</Fofa>
stream: "/path/to/script.py"
编写交互Stream
Stream其实就是和Qpipe进行通信的脚本,主要处理任务的逻辑都在这个脚本中,原理上就是通过Qpipe定时启动脚本,Qpipe会在后台启动一个http服务用来接收数据发送给AI接口,当前只支持智谱。
#!/usr/bin/env python3
import os
import requests
import pandas as pd
URL = "http://127.0.0.1:3000"
GROUP_NAME = "document_search"
def send_msg(msg: str) -> str:
response = requests.post(f"{URL}/{GROUP_NAME}", data=msg)
# print(response.text)
return response.headers['Process-ID']
def get_msg(process_id: str) -> str:
headers = {'Process-ID': process_id}
response = requests.get(f"{URL}/{GROUP_NAME}", headers=headers)
# print(response.text)
return response.text
def list_files(path: str) -> list:
files = []
for md in os.listdir(path):
if md.endswith('.md'):
files.append(md)
return files
def get_query(file_path: str) -> list:
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
if 'fofa' not in content.lower():
return []
process_id = send_msg(str(content))
result = get_msg(process_id).split(',')
return result
if __name__ == "__main__":
path = '/path/to/Poc/Markdown'
md_files = list_files(path)
query_list = []
filename = '/tmp/output.csv'
fp = open(filename, 'w', newline='')
for f in md_files:
result = get_query(file_path=os.path.join(path, f))
if len(result) == 0:
continue
try:
print(f"Query for {f} -> {result[0]}: {result[1]}")
fp.write(f"{result[0]},{result[1]}\n")
fp.flush()
except:
continue
fp.close()
由于我不是很擅长编写Prompt得到的结果不是非常理想,有时候AI提取生成的结果还是会出现意外内容:
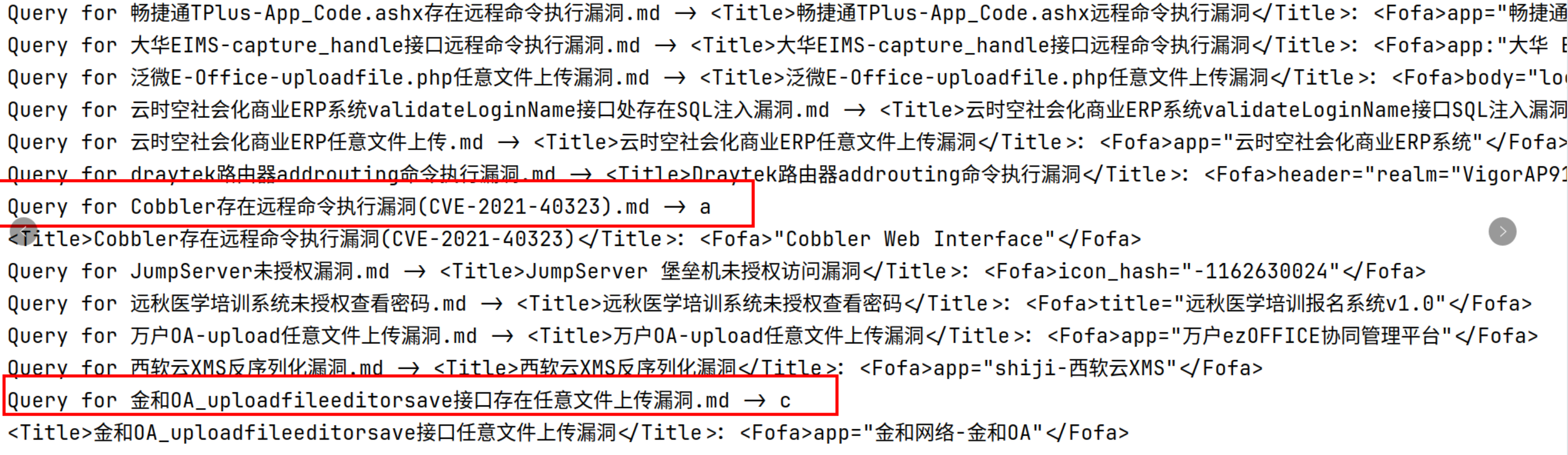
不过整体结果较好,为了提升质量,一方面需要优化配置文件中的Prompt,另外一方面倒是可以调用更强大模型。
提取的语句在这里:39ed264a2db15ec58fd13432d58c41e6

总结
通过使用Qpipe我处理了一个点赞量较高的仓库,一共筛选出来300多个Fofa查询语句,而且都是结构化的,当然Qpipe并不只是为了做这么简单的事情,它还支持定时任务启动处理,我准备把它用在工作中的运营事务上,起码可以过滤一些信息。
最后,Qpipe有点像langchain的低配低配版,而stream充当了一个个带有特殊能力的Agent,赋予了AI处理任务的能力,未来或许可以将langchain中内置的一些prompt拿来作为参考,写出更强大的配置文件。
优化后的Prompt:
# Role: 数据提取专家
## Goals
你现在是一个数据提取专家,请在我提供的文档上下文中找出 `Fofa/fofa` 下方的语句, 并总结一个漏洞标题。
## Constrains
严格按照格式输出,不需要其他多余字符。
## Skills
精通数据查找与分析
## Output format
<Title>{漏洞标题}</Title>,<Fofa>{语句}</Fofa>
## Workflow:
1. 分析文档内容,总结漏洞标题。
2. 寻找Fofa语句,如果找不到,则语句为`None`
2. 按照格式输出结果